最近深深陷在GCN大坑里不能自拔…思考如何能用GCN来干过那些采用预训练模型进行微调的获取句子表示的模型。如何干过BERT、XLNet.
分享的这篇文章是发表在18年EMNLP会议上的。这篇文章数据是用了TACRED和SemEval 2010 Task 8。
TACRED数据集要花25美元才能买到…..
虽然论文题目叫做关系抽取,其实就是给定一句话和一对实体找出其中的关系,个人感觉叫关系分类更好一些。
论文 是基于GCN的方法来获取句子和实体的语义表示。
其中论文提出了两个比较重要的点。
- 在GCN上提出了一个新的拓展模型,可以将句子的依存树结构进行编码,更好地获取句子表示和实体语义表示。
- 提出了path-centric pruning来对依存句法树进行裁剪,使其能够尽可能的删除无用信息保存有用的信息。
然后我主要是分享一下模型架构,所以主要分享一下第一点。至于如何剪支如何构建句法树这里就不介绍了。
下面先看一下整体模型架构
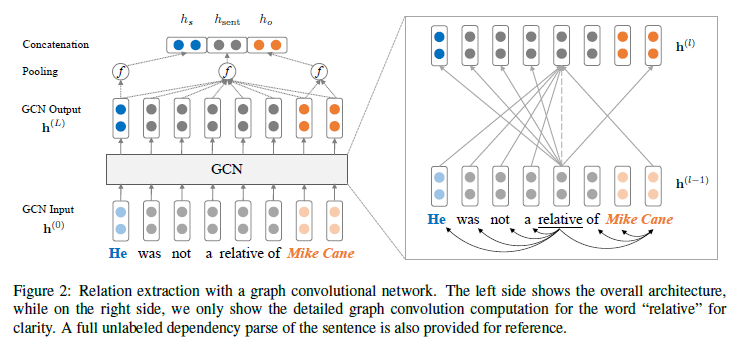
可以看到先对一句话构建依存句法树,之后构建词向量【包括先使用glove初始化的向量(300维)+pos词向量(30维)+ner词向量(30维)】其中pos和ner属于额外信息,pos就是 Part-Of-Speech Tagger。ner是标识该词如果是实体则是什么类型的实体,如果不是则是O。如下图。

之后获得获得的维度是[batch_size seq_lenth emb_dim ],之后这篇文章提出因为基于图的不能很好的捕获上下文信息,所以提出其先过一个双向的LSTM可以更好地捕获每个词的上下文信息。之后利用根据依存句法树构建的邻接矩阵一起过GCN模型。
GCN
先看看GCN的公式
但是这个邻接矩阵A因为没有加上self_loop所以在传给下一层GCN的时候自己的信息便不能很好的传到下一层,所以基于上一个公式加上self_loop。还有一个问题就是每一个顶点的度大小不同,所以需要我们正则化一下。所以修改后的GCN公式如下。
其中$\tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}$,$d_{i}=\sum_{j=1}^{n} \tilde{A}_{i j}$
GCN的代码如下,配合更有助于理解GCN。
1 | class GCN(nn.Module): |
Encoding Relations with GCN
过完GCN后如何更好地获取语义表示呢。根据上边的模型图看到,先获取句子的表示然后在获取实体的表示最后把这些语义表示相加然后过FFNN。
$h_{\text { sent }}=f\left(\mathbf{h}^{(L)}\right)=f\left(\operatorname{GCN}\left(\mathbf{h}^{(0)}\right)\right)$,$h_{\text { final }}=\mathrm{FFNN}\left(\left[h_{\text { sent }} ; h_{s} ; h_{o}\right]\right)$,hs和ho是主体实体和客体实体的表示。
这样便得到了语义表示之后就可以过一个线性分类器就可以了。
实验结果
最后贴一下论文里的实验结果图吧。
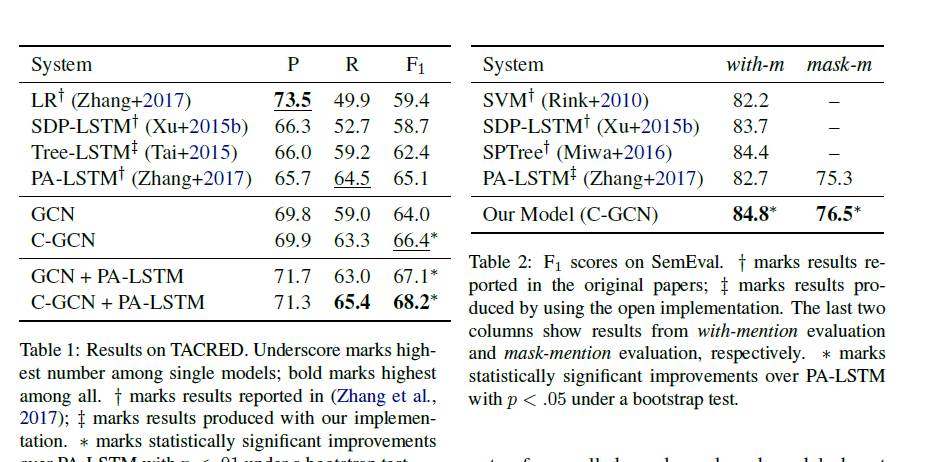
剩下一点有趣的就是这个实验为了更好地与之前论文《Positionaware attention and supervised data improve slot filling》进行对比,采取了将实体mask的策略。这篇文章做了两组实验 (1)with-mention (2)mask-mention.
mask-mention在构建词表前就将实体都替换为SUBJ-NER,OBJ-NER。这样的话在验证测试的时候实体是没有mask的。文章是这么说的encourages models to overfit to these mentions and fails to test their actual ability to generalize.其实也就是采用mask策略这样对测试验证集中的在训练集中没有出现的新实体能够获得更好地效果。
然后在这篇文章的基础上《Attention Guided Graph Convolutional Networks for Relation Extraction》提出了一个新模型不仅能够在这两个数据集上获得更好地结果,还能在cross-sentence N-ary relation extraction任务上获得好结果。。发表在了19年的ACL上。
下次分享~
最后分享一个网站 https://paperswithcode.com/sota/relation-extraction-on-tacred