语言模型
在介绍word2vec之前,不得不先来介绍一下语言模型,语言模型的本质是对一段自然语言的文本进行预测概率的大小,即如果文本用 Si 来表示,那么语言模型就是要求 P(Si) 的大小。如果按照大数定律中频率对于概率无限逼近的思想,求这个概率大小,自然要用这个文本在所有人类历史上产生过的所有文本集合中,先求这个文本的频率 P(Si) ,而后便可以通过如下公式来求得:
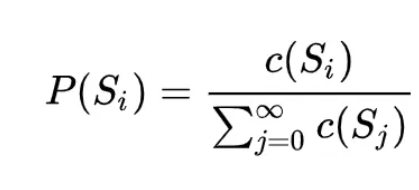
这个公式足够简单,但问题是全人类所有历史的语料这种统计显然无法实现,因此为了将这个不可能的统计任务变得可能,有人将文本不当做一个整体,而是把它拆散成一个个的词,通过每个词之间的概率关系,从而求得整个文本的概率大小。假定句子长度为 T,词用 x 表示,即:
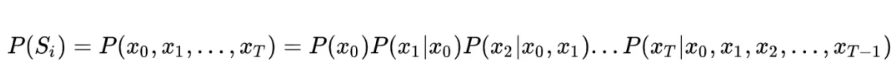
然而,这个式子的计算依然过于复杂,我们一般都会引入马尔科夫假设:假定一个句子中的词只与它前面的 n 个词相关,这个假设在HMM中也有应用。特别地,当 n=1 的时候,句子的概率计算公式最为简洁:
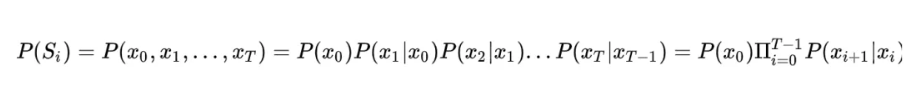
并且把词频的统计用来估计这个语言模型中的条件概率,如下:
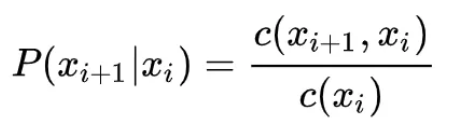
这样一来,语言模型就变得可行。然而,这种基于统计的语言模型还是存在许多问题。
第一,很多情况下C(xi+1,xi)的计算会遇到特别多零值,尤其在 n 取值较大时,这种数据稀疏导致的计算为 0 的现象变得特别严重。所以统计语言模型中一个很重要的方向便是设计各种平滑方法来处理这种情况。
第二, 另一个更为严重的问题是,基于统计的语言模型无法把 n 取得很大,一般来说在 3-gram 比较常见,再大的话,计算复杂度会指数上升。这个问题的存在导致统计语言模型无法建模语言中上下文较长的依赖关系。
第三,统计语言模型无法表征词语之间的相似性。
这个时候随着深度学习的发展便引入了NNLM。
NNLM
这些缺点的存在,迫使 2003 年 Bengio 在他的经典论文 A Neural Probabilistic Language Model 中,首次将深度学习的思想融入到语言模型中,并发现将训练得到的 NNLM(Neural Net Language Model,神经网络语言模型)模型的第一层参数当做词的分布式表征时,能够很好地获取词语之间的相似度。
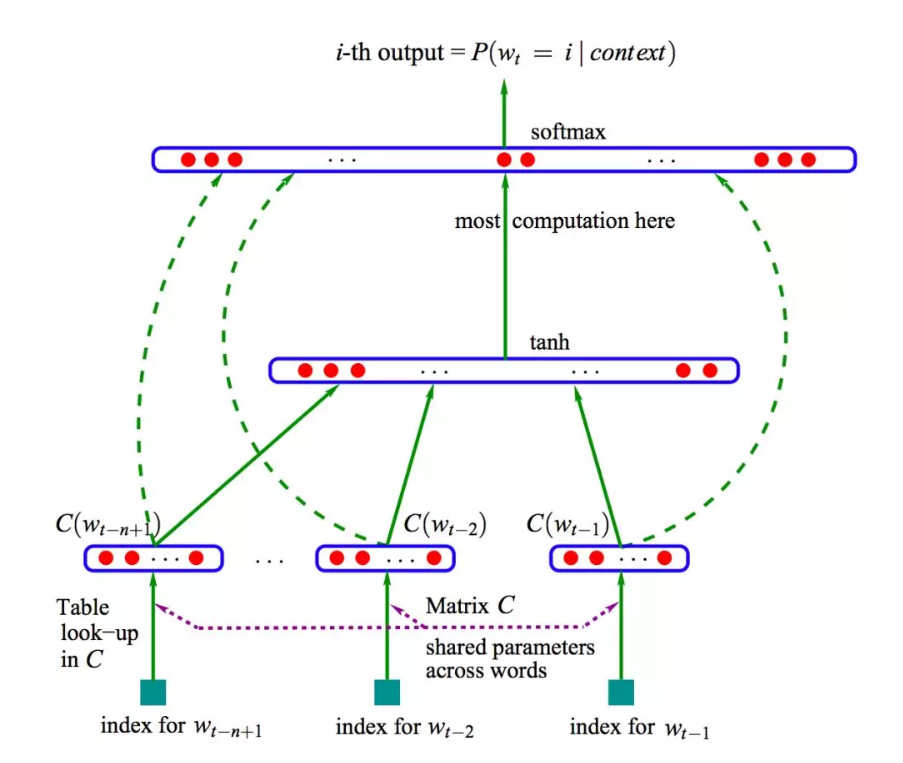
在这个模型中首先将每个词转换为one-hot向量,然后经过lookup表,映射到低维空间上,之后经过了一个隐藏层,激活函数是tanh。然后映射到词表大小的多分类上。然后利用最大似然估计取log得到目标函数来进行优化。
tanh
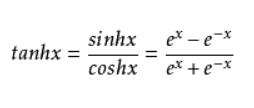
NNLM模型架构图
撇去正则化项,NNLM 的极大目标函数对数似然函数,其本质上是个 N-Gram 的语言模型,如下所示:
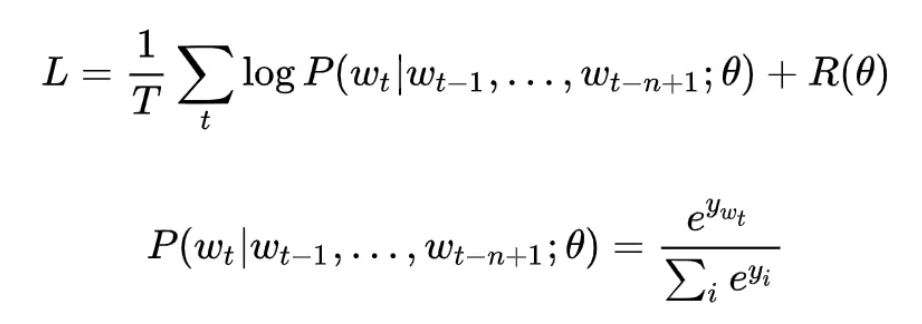
其中,归一化之前的概率大小(也就是 logits)为: 也就是经过隐藏层后。x 实际上就是将每个词映射为 m 维的向量,然后将这 n-1 个词的向量 concat 起来,组合成一个 (n-1)*m 维的向量。
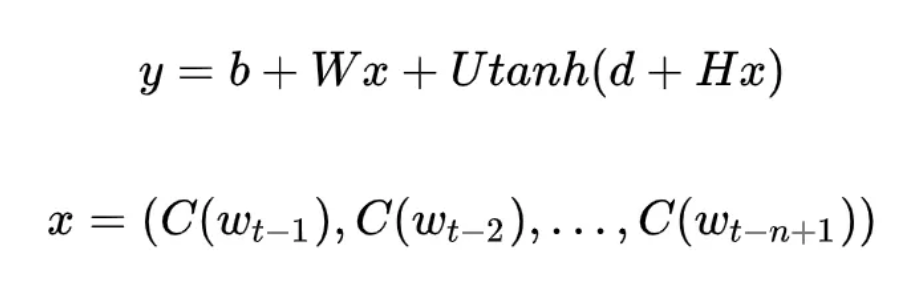
这里可以将 NNLM 的网络结构拆分为三个部分:第一部分,从词到词向量的映射,通过 C 矩阵完成映射,参数个数为 |V| m; 第二部分,从 x 到隐藏层的映射,通过矩阵 H,这里的参数个数为 |H| m (n-1); 第三部分,从隐藏层到输出层的映射,通过矩阵 U,参数个数为 |V| |H|;第四部分,从 x 到输出层的映射,通过矩阵 W,参数个数为 |V| m (n-1)。 |V|代表词汇表的大小。
因此,如果算上偏置项的参数个数(其中输出层为 |V|,输入层到隐藏层为 |H|)的话,NNLM 的参数个数为:
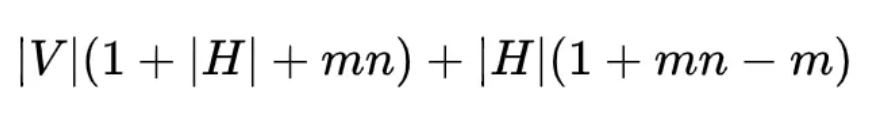
可见 NNLM 的参数个数是所取窗口大小 n 的线性函数,这便可以让 NNLM 能对更长的依赖关系进行建模。不过 NNLM 的最主要贡献是非常有创见性地将模型的第一层特征映射矩阵当做词的分布式表示,从而可以将一个词表征为一个向量形式,这直接启发了后来的 word2vec 的工作。这也是词向量的由来,在训练NNLM中,得到的副产品也就是经过lookup表映射到m维的矩阵作为参数在训练过程中不断优化,最后得到的这个矩阵就是这个词表的词向量。
NNLM的不足:
NNLM 虽然将 N-Gram 的阶 n 提高到了 5,相比原来的统计语言模型是一个很大的进步,但是为了获取更好的长程依赖关系,5 显然是不够的。再者,因为 NNLM 只对词的左侧文本进行建模,所以得到的词向量并不是语境的充分表征。
NNLM的训练依然太慢。这也就引发了word2vec中删除隐藏层的操作以及层级softmax和负采样的优化技术。
介绍完NNLM后是时候回到正轨介绍word2vec了。其中包括介绍一下word2vec的原理和两种方法以及会结合论文以及代码讲解一下两种优化算法。
word2vec
CBOW(Continuous Bag-of-Words)
是根据一个词的上下文若干次预测当前词。首先来看一下目标函数,这里Ct是Wt词的上下文。然后计算每个词wt在给点上下文的概率,利用极大似然估计之后取log得到目标函数。
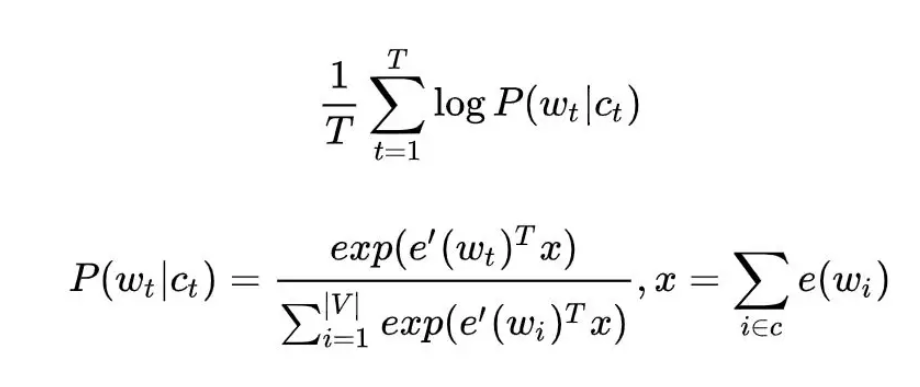
首先,CBOW 没有隐藏层,本质上只有两层结构,输入层将目标词语境 c 中的每一个词向量简单求和(当然,也可以求平均)后得到语境向量,然后直接与目标词的输出向量求点积,目标函数也就是要让这个与目标词向量的点积取得最大值,对应的与非目标词的点积尽量取得最小值。
从这可以看出,CBOW 的第一个特点是取消了 NNLM 中的隐藏层,直接将输入层和输出层相连;第二个特点便是在求语境 context 向量时候,语境内的词序已经丢弃(这个是名字中 Continuous 的来源);第三,因为最终的目标函数仍然是语言模型的目标函数,所以需要顺序遍历语料中的每一个词(这个是名字中 Bag-of-Words 的来源)。
因此有了这些特点(尤其是第二点和第三点),Mikolov 才把这个简单的模型取名叫做 CBOW,简单却有效的典范。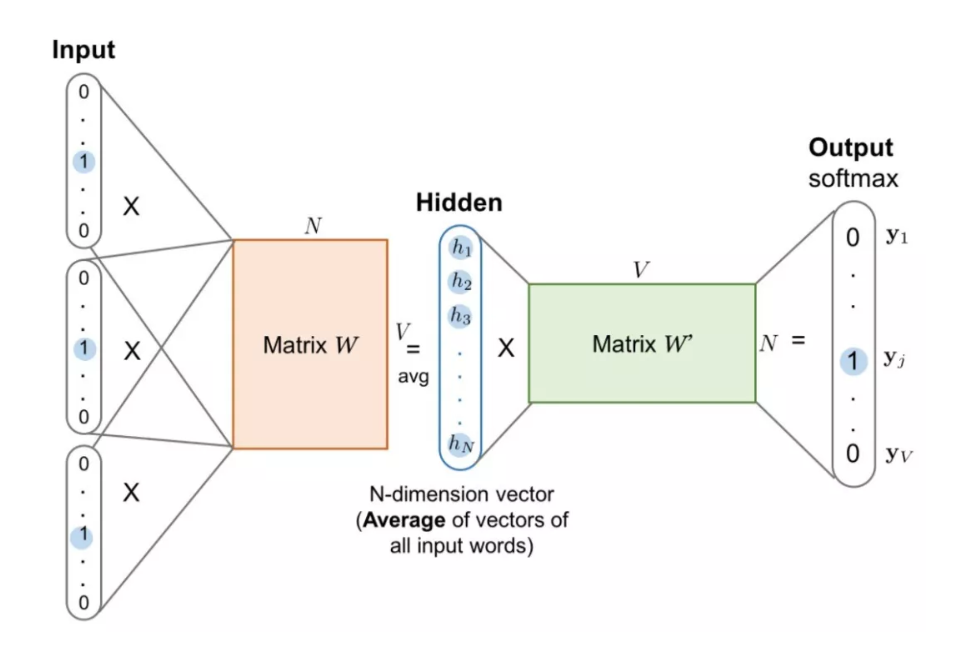
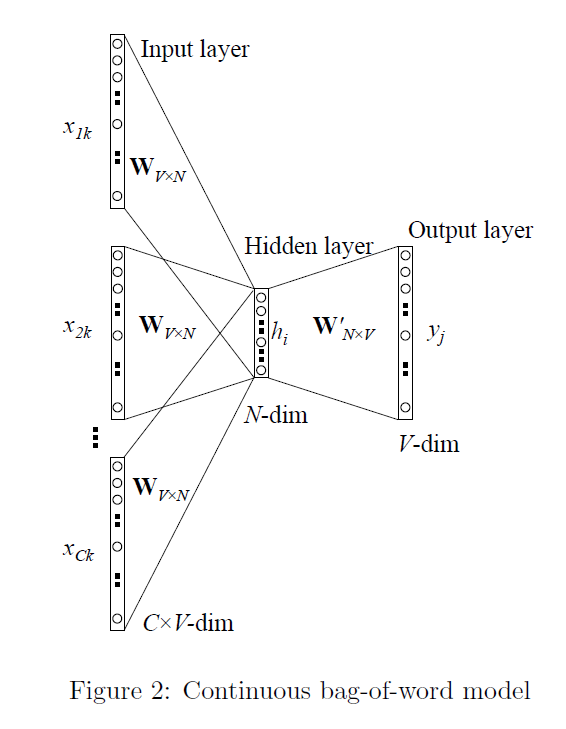
需要注意的是这里每个词对应到两个词向量,在上面的公式中都有体现,其中 e(wt) 是词的输入向量,而 e’(wt) 则是词的输出向量,或者更准确的来讲,前者是 CBOW 输入层中跟词 wt 所在位置相连的所有边的权值(其实这就是词向量)组合成的向量,而是输出层中与词 wt 所在位置相连的所有边的权值组合成的向量,所以把这一向量叫做输出向量。
Skip-gram
同样地,和 CBOW 对应,Skip-gram 的模型基本思想和 CBOW 非常类似,只是换了一个方向:CBOW 是让目标词的输出向量 e’(wt) 拟合语境的向量 x ;而 Skip-gram 则是让语境中每个词的输出向量尽量拟合当前输入词的向量 e(wt),和 CBOW 的方向相反,因此它的目标函数如下:
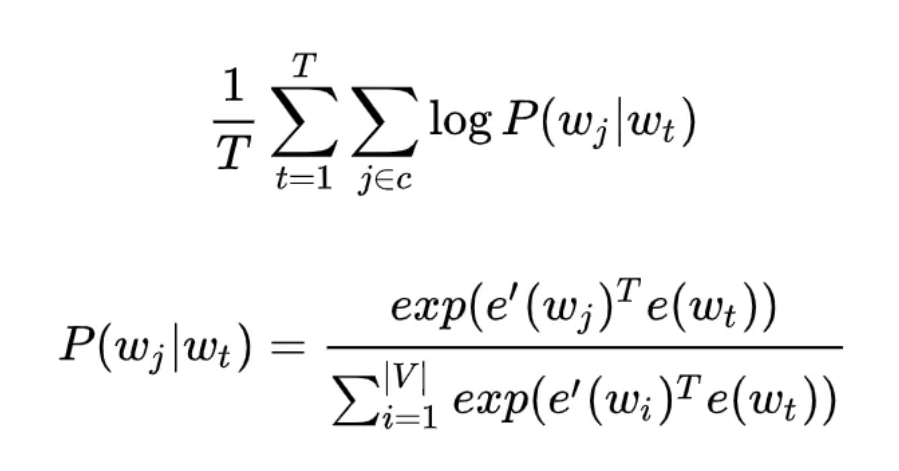
可以看出目标函数中有两个求和符号,最里面的求和符号的意义便是让当前的输入词分别和该词对应语境中的每一个词都尽量接近,从而便可以表现为该词与其上下文尽量接近。
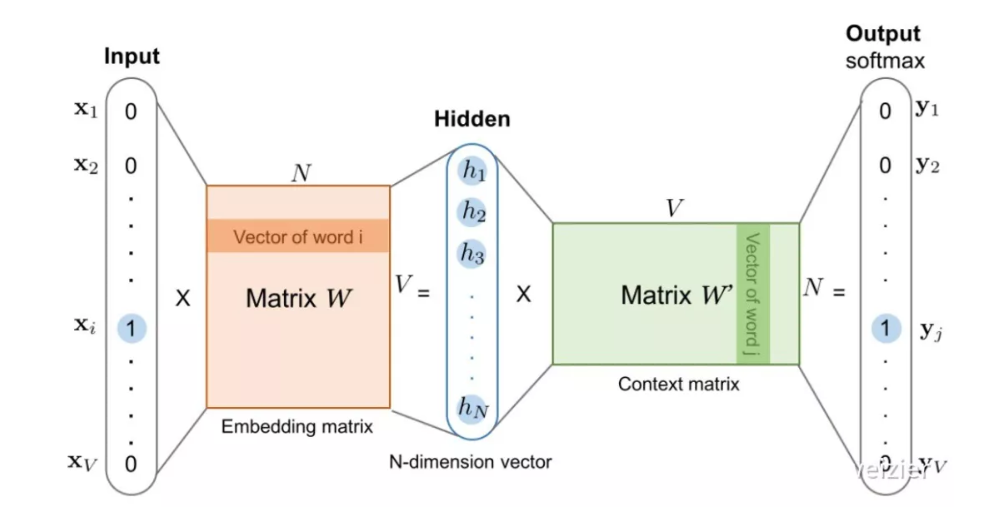
和 CBOW 类似,Skip-gram 本质上也只有两层:输入层和输出层,输入层负责将输入词映射为一个词向量,输出层负责将其经过线性映射计算得到每个词的概率大小。
再细心一点的话,其实无论 CBOW 还是 Skip-gram,本质上都是两个全连接层的相连,中间没有任何其他的层。因此,这两个模型的参数个数都是 2 × |e| × |V| ,其中 |e| 和 |V| 分别是词向量的维度和词典的大小,相比上文中我们计算得到 NNLM 的参数个数 |V|(1+|H|+|e|n) + |H|(1+|e|n-|e|) 已经大大减小,且与上下文所取词的个数无关了,也就是终于避免了 N-gram 中随着阶数 N 增大而使得计算复杂度急剧上升的问题。
但是这样也会有一个问题,当词汇表很大的时候,取softmax会消耗很大的资源和时间。所以 又提出了两种优化的方式,一种是层级采样Hierachical Softmax和另一种负采样Negative Sampling。
Hierachical Softmax
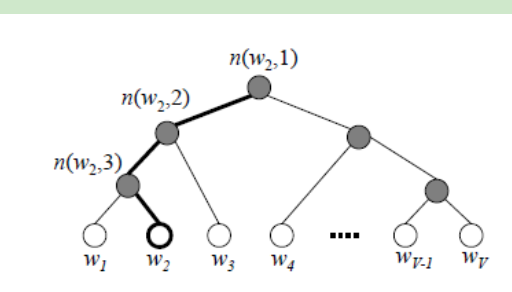
首先总的来说, Hierachical Softmax,认为这是对 full softmax 的一种优化手段,而 Hierachical Softmax 的基本思想就是首先将词典中的每个词按照词频大小构建出一棵 Huffman 树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于 Huffman 树较深层的叶子节点,每一个词都处于这棵 Huffman 树上的某个叶子节点。
第二,将原本的一个 |V| 分类问题变成了 log |V| 次的二分类问题,做法简单说来就是,原先要计算 P(wt|ct) 的时候,因为使用的是普通的 softmax,势必要求词典中的每一个词的概率大小。
为了减少这一步的计算量,在 Hierachical Softmax 中,同样是计算当前词 wt 在其上下文中的概率大小,只需要把它变成在 Huffman 树中的路径预测问题就可以了,因为当前词 wt 在 Huffman 树中对应到一条路径,这条路径由这棵二叉树中从根节点开始,经过一系列中间的父节点,最终到达当前这个词的叶子节点而组成,那么在每一个父节点上,都对应的是一个二分类问题(本质上就是一个 LR 分类器),而 Huffman 树的构造过程保证了树的深度为 log |V|,所以也就只需要做 log |V| 次二分类便可以求得 P(wt|ct) 的大小,这相比原来 |V| 次的计算量,已经大大减小了。
所以Hierachical Softmax 先构造哈夫曼树,word2vec首先对词表构建了hash,然后根据每个词出现的次数构造了哈夫曼树,这样的话,假如向左记为0,向右记为1.这样就是一个二分类问题,就是用的逻辑回归。
被划分为右子树的概率:$P(+)=\sigma\left(x_{w}^{T} \theta\right)=\frac{1}{1+e^{-x_{w}^{T} \theta}}$ 其中Xw是当前内部节点的词向量,也就是输入中间向量h,而θ则是我们需要从训练样本求出的逻辑回归的模型参数。这样的话,被划分为左子树的概率$P(-)=1-P(+)$ ,从而判断哪个概率大进而决定沿哪边走。最后将路径上的概率相乘便得到了这个划分到这个节点最终节点的概率。
对于所有样本,我们期望最大化所有样本的似然函数乘积。
定义w经过的哈夫曼树中的一个节点j的逻辑回归概率为$P\left(d_{j}^{w} | x_{w}, \theta_{j-1}^{w}\right)$,其表达式为:
其中$\sigma$ 为逻辑回归的函数。0 和 1 代表划分为左右子树的概率。那么对于一个目标输入词w,其最大似然为:
, 之后取对数似然函数L
这样便可以得到使用层级采样方法的目标函数,之后对参数和当前词的词向量进行求导更新即可。可以看到层级采样使用了二元逻辑回归求解模型参数。
但是层级采样对于词频小的词就不太友好,这就需要每次遍历到哈夫曼树的最底层。
Negative Sampling (负采样)
负采样每遍历到一个目标词,为了使得目标词的概率 P(wt|ct) 最大,根据 softmax 函数的概率公式,也就是让分子中的正样本也就是想预测词的词向量$e^{\prime}\left(w_{t}\right)^{T} x$最大,而分母中其他非目标词的$e^{\prime}\left(w_{i}\right)^{T} x$最小。
普通 softmax 的计算量太大就是因为它把词典中所有其他非目标词都当做负例了,而负采样的思想特别简单,就是每次按照一定概率随机采样一些词当做负例,从而就只需要计算这些负采样出来的负例了,那么概率公式便相应变为: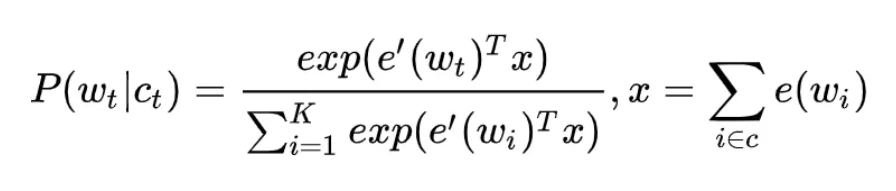
仔细和普通 softmax 进行比较便会发现,将原来的 |V| 分类问题变成了 K 分类问题,这便把词典大小对时间复杂度的影响变成了一个常数项,而改动又非常的微小,不可谓不巧妙。
首先来看一下负采样
在word2vec中 Negative Sampling也是采用了二元逻辑回归来求解模型参数。
我们的正例应该期望满足:
我们的负例期望满足:
我们期望可以最大化下式
似然函数为:
和Hierarchical Softmax类似,我们采用随机梯度上升法,仅仅每次只用一个样本更新梯度,来进行迭代更新得到我们需要的 Xw,和$\theta^{w_{i}}$ 。
word2vec中负采样的方法
在采样前,我们将这段长度为1的线段划分成M等份,这里M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
下面公式是划分词表长度的方法。划分好后,这样便可以从M个位置中采样出来的neg个位置对应上词表中的词。
1 | int hs = 0, negative = 5; |
最后贴一下层级采样和负采样的代码
1 | if (cbow) { //train the cbow architecture |
最后最后,写的有点乱,推荐看一下word2vec Parameter Learning Explained Xin Rong 这篇论文,看完会有豁然开朗的感受的。
之后会写一下Glove、fastText和word2vec的对比以及各自的优劣。
http://www.cnblogs.com/pinard/p/7243513.html
word2vec Parameter Learning Explained Xin Rong word2vec讲解不错的论文
https://cloud.tencent.com/developer/article/1066888 word2vec源码解析的一篇文章
https://github.com/tmikolov/word2vec word2vec源码