好久没更新博客了,最近正在上课,身边优秀人太多了….
疯狂充实自己ing~
正好花了点时间做了个小作业写了一个序列标注,来记录一下。
用的模型是隐马尔科夫模型HMM,用的是hmmlearn开源工具包。
当然有能力可以自己写。主要就是维特比算法。一个动态规划问题。还有就是求出来初始状态概率,词性转移概率,和发射概率即可。
HMM模型的介绍这里就不展开了,就放些代码好了。
语料是上课老师给的一个,大概40多M,90000多行。如下图:

代码一些变量命名有的都是我随意命名的…真的比较讨厌的就是起名字。平常打游戏也是,想个ID能想好久。
还有一些函数调用比较乱,然后就是代码有些for循环速度比较慢,没有优化==。
训练测试采用8:2,没有使用交叉验证,…还得从新跑模型就懒得搞了。。
数据预处理
1 | from functools import reduce |
统计词和词性从而方便计算概率
1 | import numpy as no |
计算概率和模型训练
1 | import numpy as np |
测试数据进行预测
1 | import numpy as np |
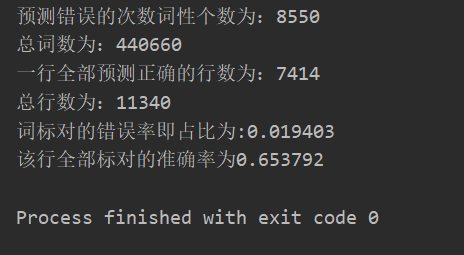
预测结果如下图:
如果所有句子词加起来统计错误率为1.9%
如果按句子来计算准确率的话 是 65.3%