本文总结了一下逻辑回归,逻辑回归用于分类,通过寻找最佳拟合参数,使用的是最优化算法。
总结了一下基于逻辑回归和Sigmoid函数的分类。
Sigmoid函数:
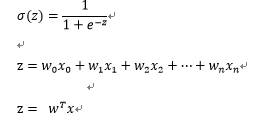
x是分类器的输入数据,是样本的特征值,w就是我们要找的最佳系数。
下面使用了批量梯度上升算法和随机梯度上升算法进行求最佳系数。
梯度下降不在详述,在下面链接可以找到梯度下降详解。
逻辑回归的梯度下降推导看如下链接:
https://blog.csdn.net/xiaoxiangzi222/article/details/55097570
批量梯度下降算法
批量梯度下降算法使对θ使用所有的样本进行更新。
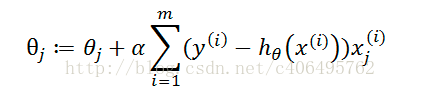
随机梯度下降算法
随机梯度下降是对θ一个样本进行更新即可
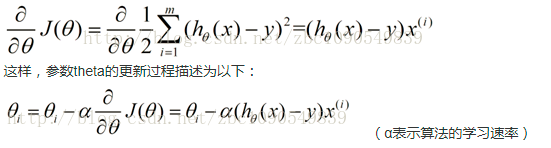
确定好算法后便可对数据进行处理,进而用梯度上升算法进行训练测试。代码如下:
1 | from numpy import * |
测试结果如下图:
