最近不太忙所以就把上次刚学python时,没能成功爬取教务系统成绩的代码又重新写了一下,但是这一写就是一段时间,其中想过很多方法,又尝试了很多方法,这过程中也摸索学到了一点知识,所以来总结一下吧。
首先打开矿大教务系统登录主页,先分析一下网页。
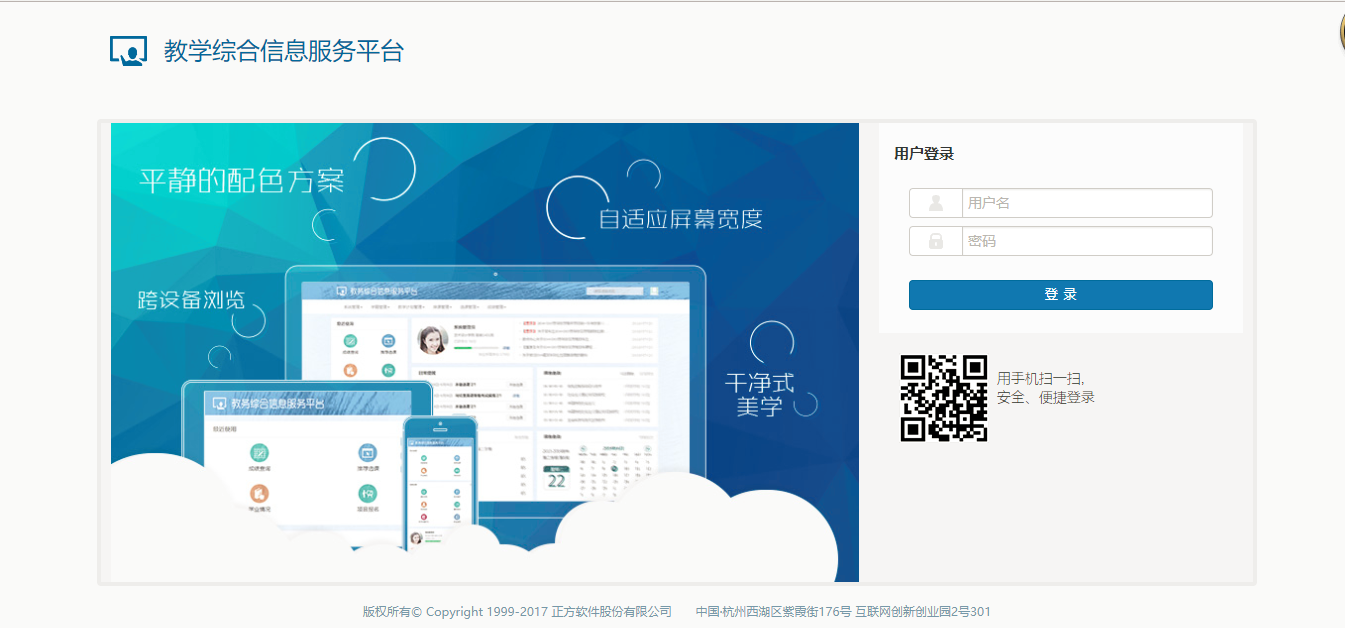
首先分析网站源代码
下面根据使用下方网址通过浏览器f12登陆进去后可以看到如下图所示的信息其中form表单有一个csrftoken,还有加密了的密码,所以简单的post用户名密码是登陆不进去网站的。
http://202.119.200.202/jwglxt/xtgl/login_slogin.html
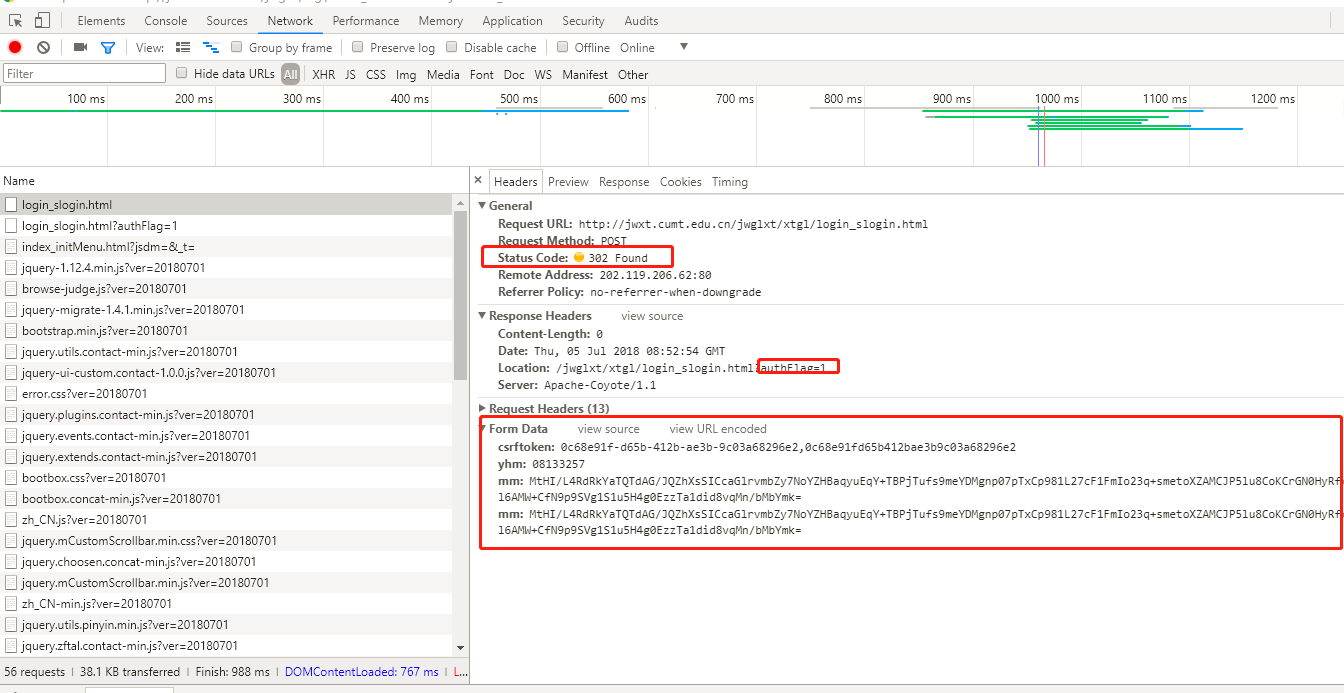
右键查看源代码可以看到首先在密码处用了autocomplete=”off”,防止浏览器自动填充密码,这或许就是我用splinter一到密码处就输不进去报错的原因吧。或许也不是,毕竟selenium还是可以成功输入的。。。
然后还可以看到此处用了一个csrftoken,可以防止csrf攻击,这也是导致了我想先登录主页保存cookies在通过分析直接跳到得到的成绩页面来爬取成绩失败的原因。所以只能考虑直接访问成绩页面跳转到登录页面,登录成功后便可以爬取到成绩。
具体怎么找到成绩页面就是根据谷歌自带的工具F12一层一层看一下就能找到,具体不详细描述了。url如下。
http://202.119.206.62/jwglxt/cjcx/cjcx_cxDgXscj.htmldoType=query&gnmkdm=N305005
1 |
|
分析加密算法
其中前四个是js加密密码用的,login.js是负责登录的js点进去看,可以看到对密码加密使用的算法。首先是定义了modulus和exponent两个变量,这两个是为了使用rsa加密算法得到公钥使用的,这两个值可以通过下方的url来得到,所以下方登录网址_t就是js里的函数得到的当前时间距离1970/1/1零点时毫秒数,这样的话密码根据时间的不同加密得到的密文也就不同。
http://jwxt.cumt.edu.cn/jwglxt/xtgl/login_slogin.html?language=zh_CN&_t=1530780180937

本来想分析js这个加密算法来通过写一个python来实现,这样就可以通过post用户名、密码在加上网页源代码可以得到的csrftoken值来登录进去了,但是无奈分析了一下发现还是没能实现成功。所以先留个坑,日后来填!
这个加密算法大致过程是先得到modulus和exponent两个变量,然后通过b64tohex函数转成16进制再通过rsa算法生成公钥,进而在利用公钥对密码加密生成私钥。然后私钥在由16进制转成base64编码即为加密密码的密文。
加密算法代码
1 | var modulus,exponent; |
下面我把用到的几个函数从那四个页面提取出来了。日后有机会用python来实现以下。
1 | // Set the public key fields N and e from hex strings |
通过以上的分析最终还是选择了selenium这个自动化测试工具,据说selenium+PhantomJS是爬虫一大杀器。
我选择了selenium+firefox ,首先需要下一个和浏览器匹配的geckodriver.exe版本。还是通过模拟浏览器登录后直接保存cookie然后爬取成绩。
爬虫代码
1 | from selenium import webdriver |
运行结果如下图
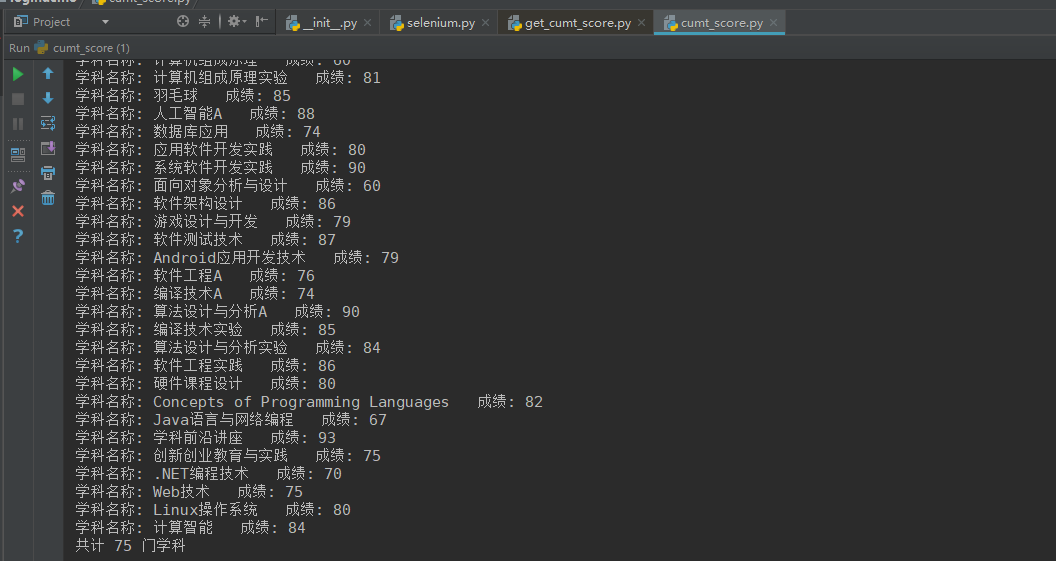
发现通过bb了一大堆代码还是如此简单…反正能爬到数据就行了是吧…基本原理还是通过cookie(客户端)和session(服务端)来实现的。
遇到动态的js如何爬取时,可以通过一层一层分析找到数据的html进而进行爬取。