朴素贝叶斯采用了属性条件独立性假设,对已知类别,假设所有属性相互独立。
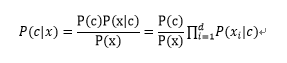
d为属性数目,xi为x在第i个属性的取值,因为对所有类别来说P(x)相同,所有只计算分子即可。
详细解释见西瓜书P150
下面说一下机器学习实战中用朴素贝叶斯算法进行文本分类。
文本训练模型算法函数(trainNB0)的步骤如下:
先将文本构建成向量
计算每个类别中的文档数目
对每篇训练文档
对每个类别:
如果词条出现在文档中>>>增加该词条的计数值
增加所有词条的计数值
最后将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率
1 | # bayes.py |
使用朴素贝叶斯过滤垃圾邮件
使用书上带的数据集进行训练,首先对邮件进行提取词然后构建向量,之后使用朴素贝叶斯算法进行训练。
1 | # email_train.py |