主要分享一下自己在学习推荐系统/计算广告的学习路程以及相关资源
Graph Convolution over Prunned Dependency Trees Improves Relation Extraction 论文笔记
最近深深陷在GCN大坑里不能自拔…思考如何能用GCN来干过那些采用预训练模型进行微调的获取句子表示的模型。如何干过BERT、XLNet.
分享的这篇文章是发表在18年EMNLP会议上的。这篇文章数据是用了TACRED和SemEval 2010 Task 8。
TACRED数据集要花25美元才能买到…..
虽然论文题目叫做关系抽取,其实就是给定一句话和一对实体找出其中的关系,个人感觉叫关系分类更好一些。
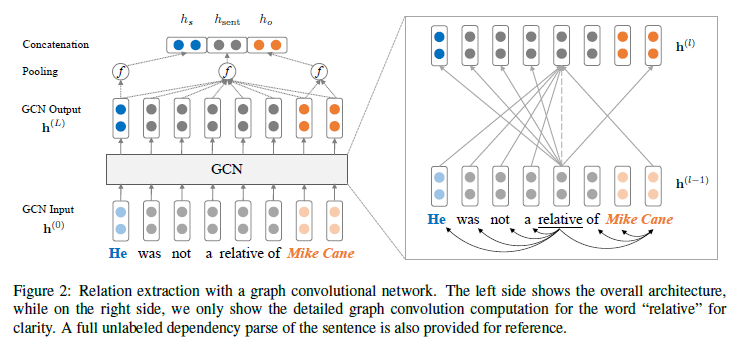
论文 是基于GCN的方法来获取句子和实体的语义表示。
其中论文提出了两个比较重要的点。
- 在GCN上提出了一个新的拓展模型,可以将句子的依存树结构进行编码,更好地获取句子表示和实体语义表示。
- 提出了path-centric pruning来对依存句法树进行裁剪,使其能够尽可能的删除无用信息保存有用的信息。
然后我主要是分享一下模型架构,所以主要分享一下第一点。至于如何剪支如何构建句法树这里就不介绍了。
下面先看一下整体模型架构

word2vec详解
语言模型
在介绍word2vec之前,不得不先来介绍一下语言模型,语言模型的本质是对一段自然语言的文本进行预测概率的大小,即如果文本用 Si 来表示,那么语言模型就是要求 P(Si) 的大小。如果按照大数定律中频率对于概率无限逼近的思想,求这个概率大小,自然要用这个文本在所有人类历史上产生过的所有文本集合中,先求这个文本的频率 P(Si) ,而后便可以通过如下公式来求得:
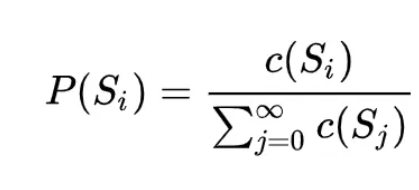
这个公式足够简单,但问题是全人类所有历史的语料这种统计显然无法实现,因此为了将这个不可能的统计任务变得可能,有人将文本不当做一个整体,而是把它拆散成一个个的词,通过每个词之间的概率关系,从而求得整个文本的概率大小。假定句子长度为 T,词用 x 表示,即:
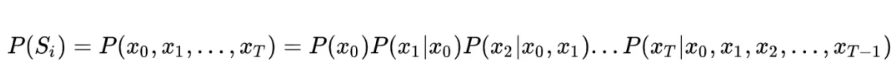
Attention系列二(代码篇)
Attention is all you need
代码都放在了github https://github.com/xuanzebi/Attention ,之后读论文如果遇到不错的其他attention机制也会继续更新。欢迎star~
attention
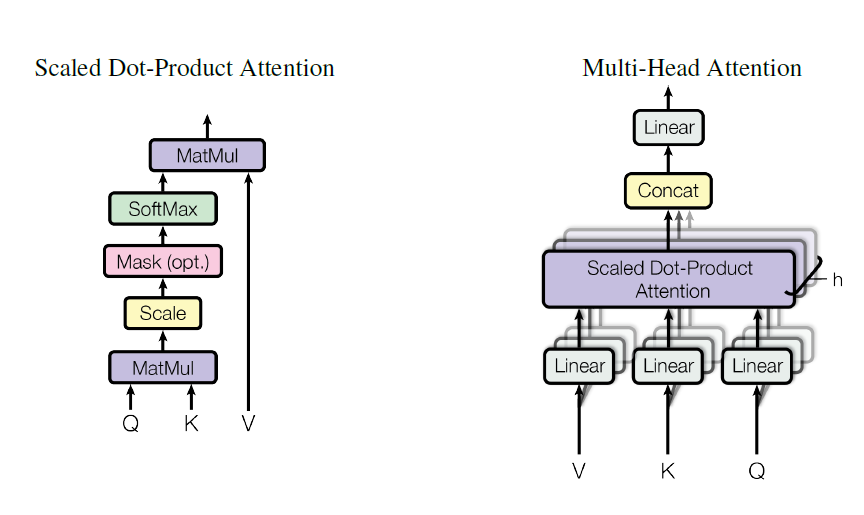
公式如下图,可以看到如果Q、K、V 都设置成对应一个文本的参数的话,就是self-attention。
Q K可以设置成对应不同词向量后的不同的参数,比如在问答中。比如aspect的情感分类Q可以设置成context,K则设置成aspect过embedding后的参数。具体可以看下方代码,通俗易懂。
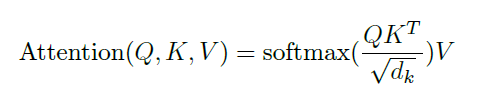
Attention系列一之seq2seq传统Attention小结
正如标题所言,本文总结了一下传统的Attention,以及介绍了在seq2seq模型中使用attention方法的不同方式。
摘要
- 首先seq2seq分为encoder和decoder两个模块,encoder和decoder可以使用LSTM、GRU等RNN结构,这也是之前transformer没出来之前常用的经典方法。(主要选取了tensorflow官方教程和pytorch教程的例子作对比来详细介绍一下。)
- 也可以在encoder和decoder使用CNN来替代RNN,主要使用了gated linear units(GRU)结构,之后详细介绍,参考论文 Convolutional Sequence to Sequence Learning
- 当然还有最近很火的transformer,它摒弃了传统的RNN、CNN等结构,使用了self-attention和Multi-Head Attention结构,下一篇文章详细介绍。Attention is all your need
声明: 有些地方理解的不够深刻或许写的不太对,希望大家都带有自己的理解去看文章,最后有哪里写的不对的欢迎大家批评指正。
kaggle Santander Customer Transaction Prediction比赛 小结
Santander Customer Transaction Prediction
之前参加了kaggle的一个Santander Customer Transaction Prediction比赛,共有达9038支队伍参赛,一个号称寻找magic的比赛。参加比赛的的忘不了被magic这个词所支配的恐惧…
比赛链接 https://www.kaggle.com/c/santander-customer-transaction-prediction/overview
也算是第一次kaggle正式的做比赛吧,之前做了一个kaggle的Quora的文本分类的一个比赛,但是只做了几天,最后还没选成 Final Score,所以最后也不算成绩,也不知道排了多少名。
我是前期做了几天,后来就没做了,直到最后四天才又开始每天做10个小时大概…
然后自己的成绩是 top4% for 9038 teams 。 288/8802..苟进了银牌区。。
很可惜最后一天模型融合没跑完比赛时间就截止了,跑完的话能再升100名…..
对自己的成绩还算满意吧。
最后感谢某位大佬的指点和带飞。
下面来总结一下这个比赛自己的收获。
Named Entity Recognition with Bidirectional LSTM-CNNs 论文阅读笔记
该论文是发表于2016年。还算是比较早的论文了。虽然现在有更好的模型。比如BERT横空出世,相信未来也会源源不断的大牛来提出更多新的模型。但是读读总还是会收获的。
之前自己也用BERT来进行中文NER的识别,代码放到了 https://github.com/xuanzebi/BERT-CH-NER 欢迎Star啊哈哈。
用HMM模型进行序列标注
好久没更新博客了,最近正在上课,身边优秀人太多了….
疯狂充实自己ing~
正好花了点时间做了个小作业写了一个序列标注,来记录一下。
用的模型是隐马尔科夫模型HMM,用的是hmmlearn开源工具包。
当然有能力可以自己写。主要就是维特比算法。一个动态规划问题。还有就是求出来初始状态概率,词性转移概率,和发射概率即可。
HMM模型的介绍这里就不展开了,就放些代码好了。